In the last post about the Six Fried Rice methodology I went over the concept of data separation and why we use it. That is essentially the starting point for how we structure the files of our system. One file contains all of the UI components and scripts for the system while a second file contains all of the actual data. Just doing that one basic separation provides several benefits that generally make life easier, but how we structure the data within the Base File itself is equally if not more important than the data separation.
To begin with I’m going to go over how we initially setup our tables. The first thing we do after we create a table is add a number field named ID that is unmodifiable and set to auto-enter a serial number. This may seem obvious to a lot of people, but as an absolute beginner I never even thought about this approach. For simplicity’s sake we never call our primary ID field anything but ID. If we ever need to store another table’s ID for relationship purposes, we use the convention `ID_ORDER` or `ID_PURCHASE_ORDER_LINE`. Naming things according to a set standard of prefixes makes organizing and locating our fields a little bit easier and saves us from a lot of hunting through long lists of names. Typically we apply this to all fields that can logically be grouped together. For example, it we have two date fields and two purchase order fields in a table, here is what our field list would look like:
- DATE_ESTIMATED_SHIP
- DATE_PROMISED
- ID
- ID_PO
- PO_VENDOR_NAME
- PO_CREATED_BY
Standards like this help us keep our fields consistent, and should I ever need to work on a table that Jesse has created I will know exactly what I’m looking at. Logically grouping your fields and giving them a standard naming convention will make navigating your data structures considerably easier.
Come to think of it, most of what our conventions are about is legibility. The simpler and more standardized you can make your systems the easier it is to come back to them at a future date and work on them after the particulars of the system have left the forefront of you mind. With that in mind here is how we approach the Anchor Buoy relationship graph setup.
Anchor Buoy is another of those concepts that like Data Separation require a little bit of additional setup in the beginning, but pays off big when you start using it in conjunction with context independent scripting and our layout design style. The basic idea is to create your Table Occurrences in several tree structures, with the root of the tree being the context that you are actually working in. Here is an example of a relatively simple database relationship structure to help get the concept across. I’ll break down the individual components and why they are setup the way they are after the image.
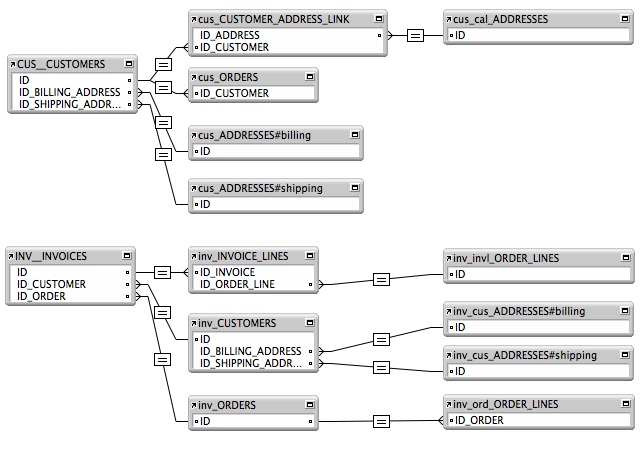
First off, there are the root tables. In this graph they would be `INV__INVOICES` and `CUS__CUSTOMERS`. These table occurrences form the root of their respective contexts and give a clear starting point to the relationships that follow. Let’s take a look at the Invoices tree to delve into how we setup these relationships and why we structure our data around them.
Any time anything happens to an invoice and any information needs to be pulled onto an invoice, the place we start is the `INV__INVOICES` table. As you can see, all of the basic information we would need for this invoice is available through some relatively simple relationships. If I need to get to the customers billing or shipping address, I can go directly through the customer table to the associated address. This setup allows me to easily and clearly identify the relationships that my data relies upon. For basic information, there is nothing more complicated than that. I would recommend labeling any table occurrences that are based on anything but the basic ID relationship. For example, when I am going to the customer’s billing and shipping addresses I have two separate occurrences of the address table using the same basic naming convention with the only difference being that I append the #shipping or #billing label to the end of the name. And just as a note, because this was the first mistake I made when trying to use Anchor Buoy for the first time, never link a layout to anything but one of the root tables. Using one of the buoy tables that is further down stream than the root can create all types of context issues when scripting and setting up calculations. I can’t stress how many headaches you can avoid by having only one context to that you work in!
Now, calculations. Let’s say I wanted to store the order total on the order record itself, and I wanted to pull the total directly from the order lines associated with the order. Using the base table system, the context I would start in is `ORD__ORDERS`. From there, I would pull the sum of the order lines from the `ord_ORDER_LINES` table occurrence. This one calculation will now be the only place where the order gets it’s total price from. So, when I want to display the order total on the invoice itself I would just grab that calculated total from the `inv_ORDERS` occurrence. Basically the goal is to always set your data structure up so that your base tables do all the work of gathering information and creating contexts that will allow you to easily traverse your data when you are scripting and designing your layouts.
The end goal of using Anchor Buoy and Data Separation is to lay the ground work for a development environment that is simple to understand, powerful to work within and flexible enough to handle most any scenario that a customer can come up with. Once you have this base in place, using our scripting methods and layout design has the potential to greatly reduce the complexity of development. The next post will focus mainly on setting up the basic operating layouts we use and how we script around them to provide fully encapsulated and single point functionality.